Semantic Segmentation using Deep Convolutional Neural Networks


 The Freiburg Forest
dataset was collected using our Viona autonomous mobile robot
platform equipped with cameras for capturing multi-spectral and
multi-modal images. The dataset may be used for evaluation of
different perception algorithms for segmentation, detection,
classification, etc. All scenes were recorded at 20 Hz with a camera
resolution of 1024x768 pixels. The data was collected on three
different days to have enough variability in lighting conditions as
shadows and sun angles play a crucial role in the quality of
acquired images. The robot traversed about 4.7 km each day. We
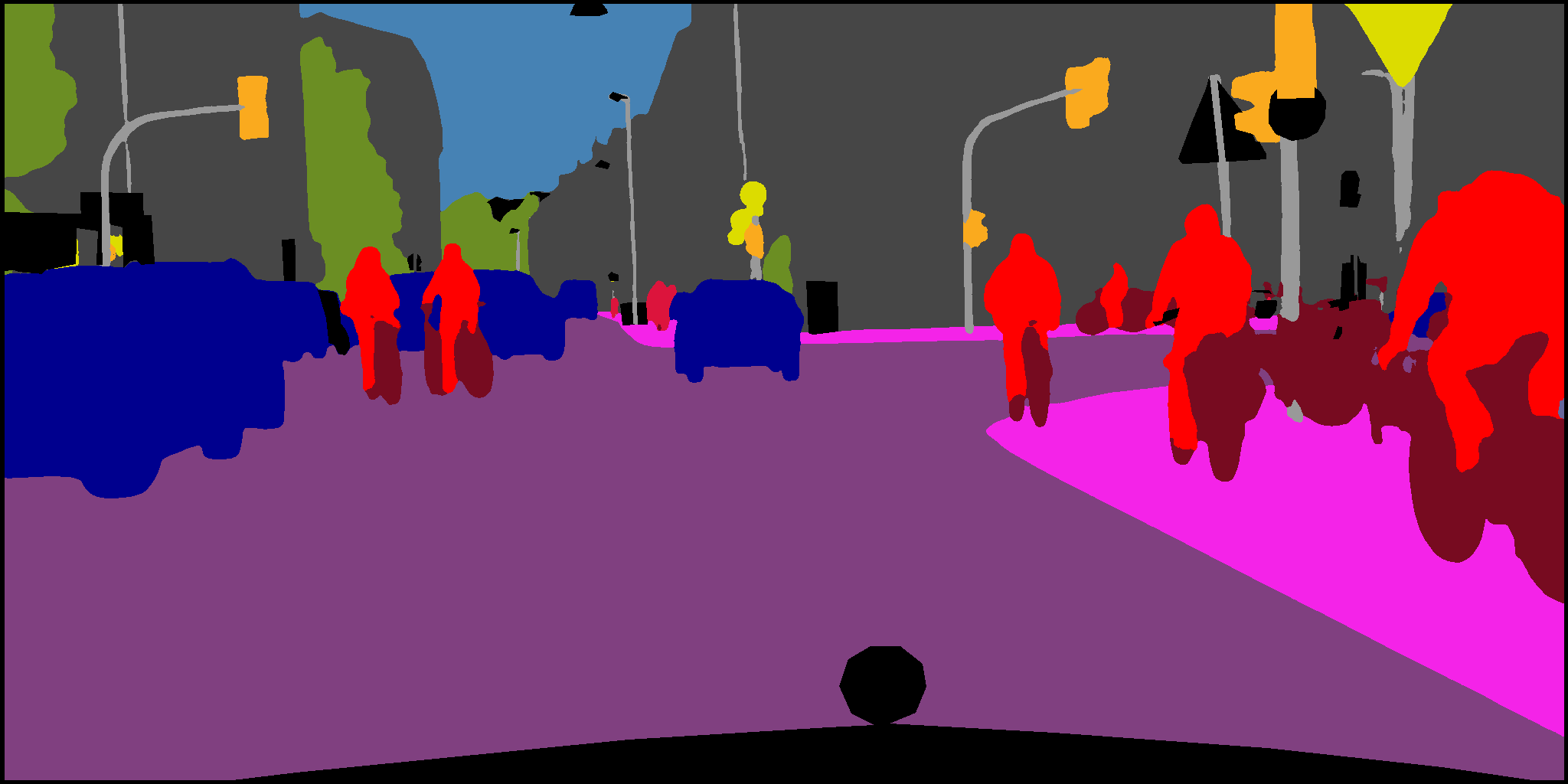
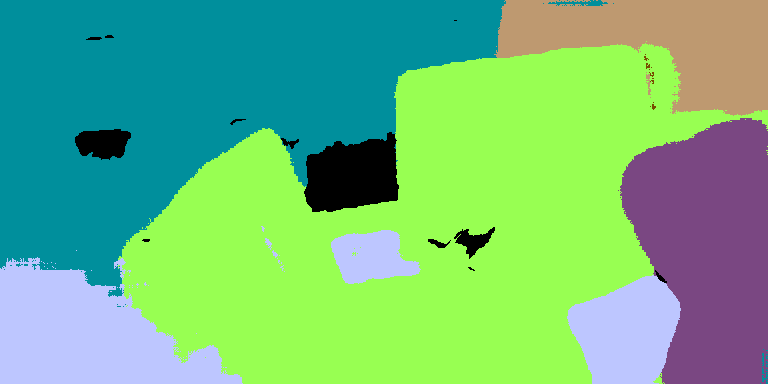
provide manually annotated pixel-wise ground truth segmentation masks for 6 classes:
Obstacle, Trail, Sky, Grass, Vegetation, and Void.
The Freiburg Forest
dataset was collected using our Viona autonomous mobile robot
platform equipped with cameras for capturing multi-spectral and
multi-modal images. The dataset may be used for evaluation of
different perception algorithms for segmentation, detection,
classification, etc. All scenes were recorded at 20 Hz with a camera
resolution of 1024x768 pixels. The data was collected on three
different days to have enough variability in lighting conditions as
shadows and sun angles play a crucial role in the quality of
acquired images. The robot traversed about 4.7 km each day. We
provide manually annotated pixel-wise ground truth segmentation masks for 6 classes:
Obstacle, Trail, Sky, Grass, Vegetation, and Void.
For each spectrum/modality, we provide one zip file containing all the sequences. Each sequence is a continous stream of camera frames. All the multi-spectral images are in the PNG format and the depth images are in the 16-bit TIFF format. For the evaluations mentioned in the paper, we provide two text files containing the train and test splits. If you would like to contribute to the annotations, please contact us. More details and evaluations can be found in our papers listed under publications.
Please cite our work if you use the Freiburg Forest Dataset or report results based on it.
@InProceedings{valada16iser,
author = {Abhinav Valada and Gabriel Oliveira and Thomas Brox and Wolfram Burgard},
title = {Deep Multispectral Semantic Scene Understanding of Forested Environments using Multimodal Fusion},
booktitle = {International Symposium on Experimental Robotics (ISER)},
year = {2016},
}The data is provided for non-commercial use only. By downloading the data, you accept the license agreement which can be downloaded here. If you report results based on the Freiburg Forest datasets, please consider citing the paper mentioned above.

The raw dataset contains over 15,000 images of unstructued forest environments, captured at 20Hz using our Viona autonomous robot platform equipped with a Bumblebee2 stereo vision camera.

The dataset contains the following multi-modal/spectral images with groundtruth annotations: RGB, Depth, NIR, NRG, NDVI, EVI and their variants. Pixel-level annotations are provided for 6 semantic classes: Trail, Grass, Vegetation, Obstacle, Sky, Void.